目录
DrissionRouter:基于 DrissionPage 的网络请求拦截与修改利器
引言
在浏览器自动化领域,Playwright 的网络拦截功能一直备受开发者青睐。通过拦截、修改请求和响应,开发者能够实现 Mock 数据、注入脚本、调试 API 等多种高级用途。然而,对于使用 DrissionPage 作为主要自动化工具的开发者来说,长期以来一直缺少一个对等的网络拦截方案。
本文将详细介绍 DrissionRouter——一个模仿 Playwright 网络拦截器 API 设计的 DrissionPage 扩展库,它通过 Chrome DevTools Protocol(CDP)实现了完整的请求拦截、修改、伪造和拒绝功能。
核心架构
DrissionRouter 由两个核心类组成:DrissionRouterRequest 和 DrissionRouter。整体架构基于 CDP 的 Fetch 域,通过在浏览器层面拦截请求,实现对网络流量的精细控制。
类关系图
DrissionRouter ├── page_or_tab: ChromiumPage | ChromiumTab ├── url_fun_map: Dict[str, Callable] # URL 模式到回调函数的映射 ├── kwargs_map: Dict[str, Dict] # URL 模式到回调参数的映射 ├── intercept(url, callback, **kwargs) # 注册拦截规则 ├── start_intercept() # 启动拦截 └── end_intercept() # 终止拦截 DrissionRouterRequest ├── page_or_tab # 页面/标签页引用 ├── status: int # 响应状态码 ├── request_id: str # 请求唯一标识 ├── request: Dict # 请求详情(URL、Method、Headers、Body) ├── response_headers: List # 响应头 ├── resource_type: str # 资源类型(XHR、Document 等) ├── continue_(...) # 继续请求(可修改) ├── fulfill(...) # 伪造响应 ├── abort(...) # 拒绝请求 └── get_response(...) # 获取响应体
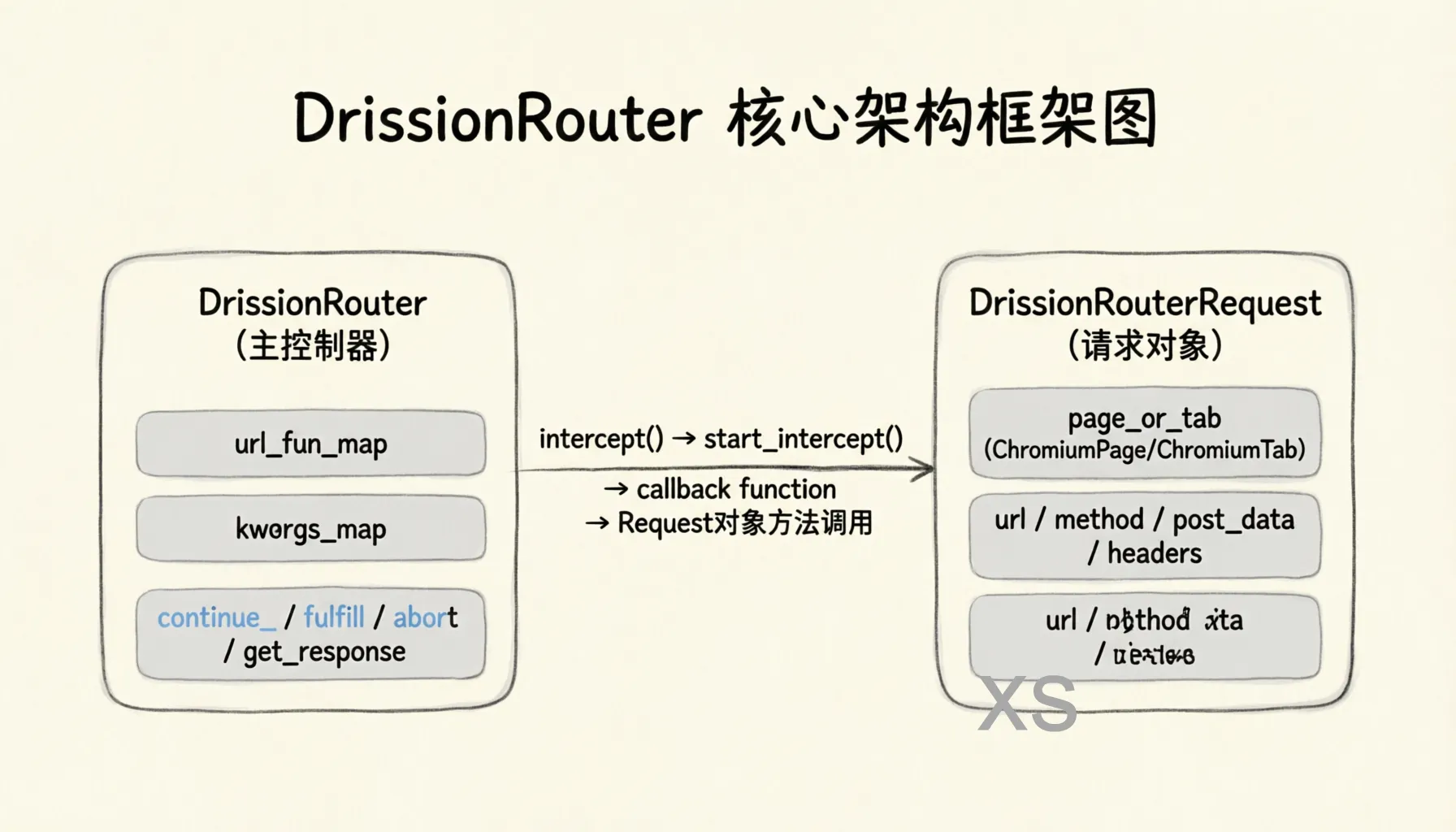 图:DrissionRouter 核心架构——两个核心类的属性与方法关系
图:DrissionRouter 核心架构——两个核心类的属性与方法关系
技术原理
Chrome DevTools Protocol Fetch 域
DrissionRouter 的核心依赖于 CDP 的 Fetch 域,该域提供了拦截浏览器网络请求的能力。工作流程如下:
-
启用拦截:通过
Fetch.enable命令注册需要拦截的 URL 模式,浏览器会在匹配请求发出前暂停该请求。 -
接收暂停事件:当请求被拦截时,CDP 触发
Fetch.requestPaused事件,携带请求的所有详细信息。 -
处理请求:开发者可以选择以下三种操作之一:
Fetch.continueRequest:继续发送请求(可修改 URL、Method、Headers、Body)Fetch.fulfillRequest:直接返回伪造的响应,不经过真实服务器Fetch.failRequest:拒绝请求,模拟网络错误
-
获取响应体:通过
Fetch.getResponseBody获取已拦截请求的响应内容,可用于响应修改场景。
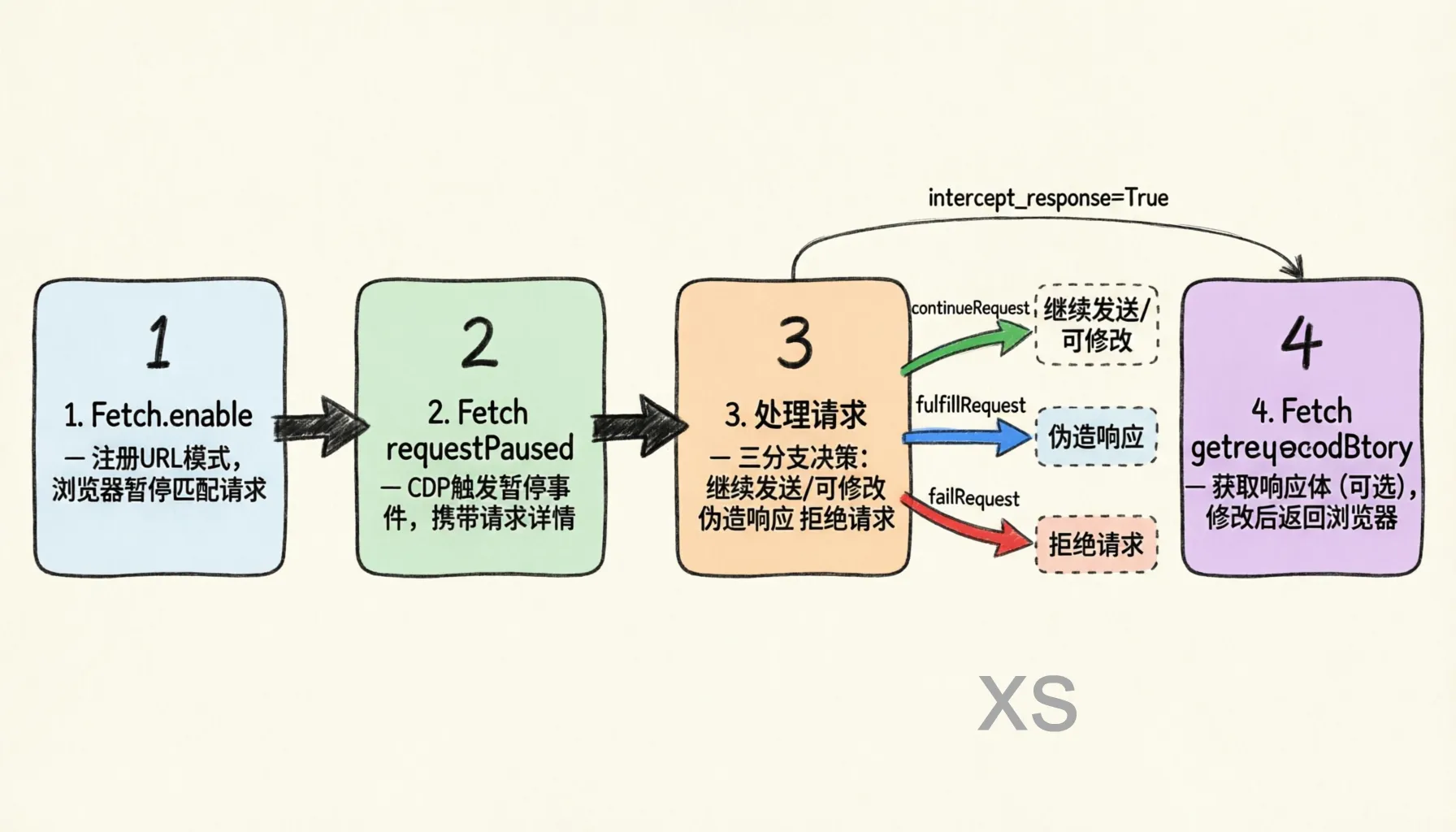 图:CDP Fetch 域完整工作流程——启用拦截 → 接收暂停事件 → 处理请求 → 获取响应体
图:CDP Fetch 域完整工作流程——启用拦截 → 接收暂停事件 → 处理请求 → 获取响应体
关键实现细节
1. 请求对象的封装
DrissionRouterRequest 封装了单个被拦截请求的所有信息,提供了便捷的属性访问和方法调用:
python@property
def url(self) -> str:
return self.request.get('url')
@property
def method(self) -> str:
return self.request.get('method')
@property
def post_data(self):
return self.request.get('postData', {})
@property
def headers(self) -> dict:
return self.request.get("headers", {})
2. Base64 编码处理
CDP 协议要求 postData 和响应体以 Base64 编码传输。continue_ 和 fulfill 方法内部自动处理了编码转换:
python# 请求体编码
byte_data = post_data.encode('utf-8')
base64_encoded = base64.b64encode(byte_data)
base64_string = base64_encoded.decode('utf-8')
params["postData"] = base64_string
params["postDataEntries"] = [{"bytes": base64_string}]
# 响应体解码
response = self.page_or_tab.driver.run("Fetch.getResponseBody", requestId=self.request_id)
body = response.get("body")
if body:
data = base64.b64decode(body).decode('utf-8')
3. URL 模式匹配
DrissionRouter 使用 Python 标准库的 fnmatch 实现通配符匹配,同时支持直接的子字符串匹配:
pythonfor key in self.url_fun_map.keys():
if fnmatch.fnmatch(url, key) or key in url:
callback = self.url_fun_map[key]
kwargs = self.kwargs_map.get(key, {})
callback(request, **kwargs)
break
这意味着你可以使用 *、? 等通配符,也可以直接写 URL 片段。
4. 两阶段拦截机制
通过 intercept_response=True 参数,可以实现响应体的拦截和修改。当回调函数被调用两次时:
- 第一次调用:请求发出阶段,可以修改请求
- 第二次调用:响应返回阶段,可以修改响应体
get_response 方法提供了自动填充响应的机制,如果未手动调用 continue_,会自动填充原始响应以确保请求正常传递到浏览器。
安装与依赖
bashpip install DrissionPage loguru
将 drission_router.py 文件放入你的项目中即可使用。
完整使用指南
基础用法:拦截并修改请求
以下示例演示如何拦截特定 API 请求并修改请求参数:
pythonfrom DrissionPage import ChromiumPage
from drission_router import DrissionRouter
page = ChromiumPage()
router = DrissionRouter(page)
def modify_api_request(request, **kwargs):
"""修改请求的 URL 和请求体"""
print(f"拦截到请求: {request.url}")
print(f"请求方法: {request.method}")
print(f"请求头: {request.headers}")
# 修改请求体
original_data = request.post_data
modified_data = original_data.copy()
modified_data['page'] = 1 # 修改分页参数
request.continue_(
post_data=modified_data,
headers={'X-Custom-Header': 'my-value'}
)
# 注册拦截规则
router.intercept('*/api/data*', modify_api_request)
# 启动拦截
router.start_intercept()
# 访问页面
page.get('https://example.com')
# 需要时终止拦截
router.end_intercept()
Mock 响应数据
伪造服务器响应是测试场景中的常见需求:
pythondef mock_api_response(request, **kwargs):
"""直接返回 Mock 数据,不经过真实服务器"""
mock_data = {
"code": 200,
"message": "success",
"data": {
"users": [
{"id": 1, "name": "张三", "email": "zhangsan@example.com"},
{"id": 2, "name": "李四", "email": "lisi@example.com"}
],
"total": 2
}
}
request.fulfill(
response_code=200,
body=mock_data
)
router.intercept('*/api/users*', mock_api_response)
router.start_intercept()
修改响应内容
拦截真实响应并修改后返回给浏览器:
pythonimport json
def modify_api_response(request, **kwargs):
"""获取真实响应并修改内容"""
# 获取原始响应
original_body = request.get_response(is_auto_fill_response=False)
if original_body:
try:
data = json.loads(original_body)
# 修改响应数据
if 'data' in data and 'users' in data['data']:
for user in data['data']['users']:
user['name'] = f"[已修改] {user['name']}"
# 将修改后的响应返回给浏览器
request.fulfill(
response_code=request.status,
body=data
)
except json.JSONDecodeError:
# 如果不是 JSON,直接返回原始响应
request.fulfill(
response_code=request.status,
body=original_body
)
else:
# 没有响应体时,继续原始请求
request.continue_()
router.intercept('*/api/users*', modify_api_response)
router.start_intercept()
拒绝特定请求
模拟网络错误或阻止特定请求:
pythonfrom drission_router import DrissionRouter
def block_tracking_request(request, **kwargs):
"""拒绝请求,模拟被客户端阻止"""
request.abort("BlockedByClient")
router.intercept('*/tracking*', block_tracking_request)
router.start_intercept()
注入自定义 Headers
为所有请求添加统一的认证头:
pythondef add_auth_header(request, **kwargs):
"""为请求添加 Authorization 头"""
headers = request.headers
headers['Authorization'] = 'Bearer your-token-here'
headers['X-Request-ID'] = kwargs.get('request_id', 'default-id')
request.continue_(headers=headers)
router.intercept('*/api/*', add_auth_header, request_id='req-12345')
router.start_intercept()
重定向请求
将请求重定向到其他 URL:
pythondef redirect_request(request, **kwargs):
"""将请求重定向到测试环境"""
original_url = request.url
new_url = original_url.replace('production.example.com', 'staging.example.com')
print(f"重定向: {original_url} -> {new_url}")
request.continue_(url=new_url)
router.intercept('*/production.example.com/*', redirect_request)
router.start_intercept()
多标签页拦截
DrissionRouter 同样支持对单个 Tab 进行拦截:
pythonfrom DrissionPage import ChromiumPage
page = ChromiumPage()
tabs = page.get_tabs()
# 对特定标签页进行拦截
tab_router = DrissionRouter(tabs[0])
tab_router.intercept('*/api/*', lambda req, **kw: print(f"Tab 拦截: {req.url}"))
tab_router.start_intercept()
错误处理与调试
错误原因枚举
abort 方法支持以下标准错误原因:
| 错误原因 | 说明 |
|---|---|
Failed | 通用失败 |
Aborted | 请求被中止 |
TimedOut | 请求超时 |
AccessDenied | 访问被拒绝 |
ConnectionClosed | 连接已关闭 |
ConnectionReset | 连接被重置 |
ConnectionRefused | 连接被拒绝 |
ConnectionAborted | 连接被中止 |
ConnectionFailed | 连接失败 |
NameNotResolved | DNS 解析失败 |
InternetDisconnected | 网络断开 |
AddressUnreachable | 地址不可达 |
BlockedByClient | 被客户端阻止 |
BlockedByResponse | 被响应阻止 |
调试技巧
pythonfrom loguru import logger
# 开启详细日志
logger.add("drission_router.log", rotation="10 MB")
def debug_interceptor(request, **kwargs):
"""打印所有请求信息的调试拦截器"""
logger.info(f"=== 拦截请求 ===")
logger.info(f"URL: {request.url}")
logger.info(f"Method: {request.method}")
logger.info(f"Headers: {request.headers}")
logger.info(f"Post Data: {request.post_data}")
logger.info(f"Resource Type: {request.resource_type}")
logger.info(f"Status: {request.status}")
logger.info(f"Request ID: {request.request_id}")
# 继续原始请求
request.continue_()
router.intercept('*', debug_interceptor)
router.start_intercept()
高级应用场景
场景一:API Mock 服务器
构建一个轻量级的本地 Mock 服务,无需启动额外的服务器:
pythonimport json
from drission_router import DrissionRouter
class MockServer:
def __init__(self, page):
self.router = DrissionRouter(page)
self.routes = {}
def get(self, path, response_data):
self.routes[path] = {"method": "GET", "response": response_data}
def post(self, path, response_data):
self.routes[path] = {"method": "POST", "response": response_data}
def _handler(self, request, **kwargs):
for pattern, route in self.routes.items():
if pattern in request.url:
request.fulfill(
response_code=200,
body=route["response"]
)
return
request.continue_()
def start(self):
for path in self.routes:
self.router.intercept(f'*{path}*', self._handler)
self.router.start_intercept()
def stop(self):
self.router.end_intercept()
# 使用示例
mock = MockServer(page)
mock.get('/api/users', {
"users": [{"id": 1, "name": "Mock User"}]
})
mock.post('/api/login', {
"token": "mock-jwt-token",
"user": {"id": 1, "name": "Admin"}
})
mock.start()
场景二:性能分析拦截器
记录所有网络请求的性能数据:
pythonimport time
from collections import defaultdict
class PerformanceMonitor:
def __init__(self, page):
self.router = DrissionRouter(page)
self.stats = defaultdict(list)
self.start_times = {}
def _record_request(self, request, **kwargs):
self.start_times[request.request_id] = time.time()
request.continue_(intercept_response=True)
def _record_response(self, request, **kwargs):
if request.request_id in self.start_times:
duration = time.time() - self.start_times[request.request_id]
self.stats[request.resource_type].append({
'url': request.url,
'duration': duration,
'status': request.status
})
request.continue_()
def start(self):
self.router.intercept('*', self._record_request)
self.router.start_intercept()
def get_report(self):
report = {}
for resource_type, records in self.stats.items():
avg_duration = sum(r['duration'] for r in records) / len(records)
report[resource_type] = {
'count': len(records),
'avg_duration': f"{avg_duration:.3f}s",
'slowest': max(records, key=lambda x: x['duration'])
}
return report
def stop(self):
self.router.end_intercept()
# 使用示例
monitor = PerformanceMonitor(page)
monitor.start()
page.get('https://example.com')
# ... 执行操作 ...
print(json.dumps(monitor.get_report(), indent=2, ensure_ascii=False))
monitor.stop()
场景三:请求日志与回放
记录所有请求,用于后续回放和测试:
pythonimport json
import os
from datetime import datetime
class RequestRecorder:
def __init__(self, page, log_dir='./request_logs'):
self.router = DrissionRouter(page)
self.log_dir = log_dir
self.records = []
os.makedirs(log_dir, exist_ok=True)
def _record(self, request, **kwargs):
record = {
'url': request.url,
'method': request.method,
'headers': request.headers,
'post_data': request.post_data,
'resource_type': request.resource_type,
'timestamp': datetime.now().isoformat()
}
self.records.append(record)
request.continue_()
def start(self):
self.router.intercept('*', self._record)
self.router.start_intercept()
def save(self, filename=None):
if filename is None:
filename = f"requests_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json"
filepath = os.path.join(self.log_dir, filename)
with open(filepath, 'w', encoding='utf-8') as f:
json.dump(self.records, f, ensure_ascii=False, indent=2)
print(f"已保存 {len(self.records)} 条请求记录到 {filepath}")
def stop(self):
self.router.end_intercept()
# 使用示例
recorder = RequestRecorder(page)
recorder.start()
page.get('https://example.com')
# ... 执行操作 ...
recorder.save()
recorder.stop()
场景四:条件拦截器
根据请求条件动态决定拦截行为:
pythonclass ConditionalInterceptor:
def __init__(self, page):
self.router = DrissionRouter(page)
self.conditions = []
def add_condition(self, url_pattern, condition, action):
"""
添加条件拦截规则
:param url_pattern: URL 匹配模式
:param condition: 条件函数,接收 request 参数,返回 bool
:param action: 动作函数,接收 request 参数
"""
def handler(request, **kwargs):
if condition(request):
action(request)
else:
request.continue_()
self.router.intercept(url_pattern, handler)
def start(self):
self.router.start_intercept()
def stop(self):
self.router.end_intercept()
# 使用示例
interceptor = ConditionalInterceptor(page)
# 只对 POST 请求添加 header
interceptor.add_condition(
'*/api/*',
lambda req: req.method == 'POST',
lambda req: req.continue_(headers={'X-CSRF-Token': 'test-token'})
)
# 拒绝大体积请求
interceptor.add_condition(
'*/upload/*',
lambda req: len(str(req.post_data)) > 10000,
lambda req: req.abort('Aborted')
)
interceptor.start()
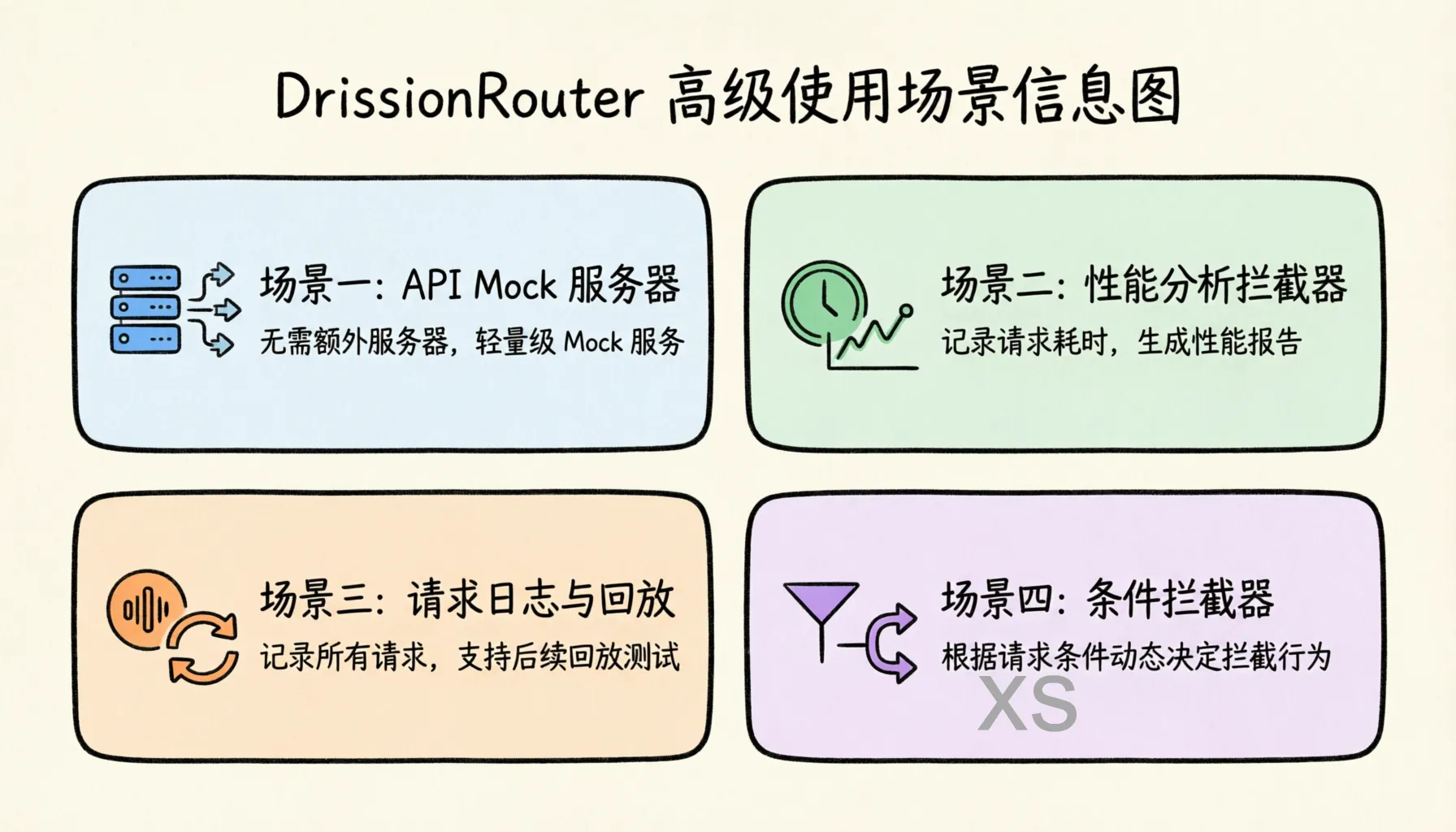 图:四种高级应用场景——API Mock 服务器、性能分析拦截器、请求日志与回放、条件拦截器
图:四种高级应用场景——API Mock 服务器、性能分析拦截器、请求日志与回放、条件拦截器
与 Playwright 对比
| 特性 | Playwright | DrissionRouter |
|---|---|---|
| 请求拦截 | page.route() | router.intercept() |
| 修改请求 | route.continue_() | request.continue_() |
| 伪造响应 | route.fulfill() | request.fulfill() |
| 拒绝请求 | route.abort() | request.abort() |
| 获取响应体 | response.body() | request.get_response() |
| 通配符匹配 | glob 语法 | fnmatch + 子字符串 |
| 多标签页支持 | 原生支持 | 通过 Tab 对象支持 |
 图:Playwright 与 DrissionRouter API 功能对等关系对比
图:Playwright 与 DrissionRouter API 功能对等关系对比
实战项目:完整的 API 调试工作流
下面是一个完整的实战项目,展示如何将 DrissionRouter 应用于日常的 API 调试和测试工作流。
项目目标
在浏览器自动化测试中,我们需要:
- 拦截所有
/api/*请求 - 为每个请求添加认证 Token
- 记录请求和响应的完整日志
- 对特定接口返回 Mock 数据
- 生成测试报告
完整实现
pythonimport json
import time
from datetime import datetime
from pathlib import Path
from DrissionPage import ChromiumPage
from drission_router import DrissionRouter
class APITestWorkflow:
def __init__(self, page: ChromiumPage, token: str, mock_routes: dict = None):
self.page = page
self.router = DrissionRouter(page)
self.token = token
self.mock_routes = mock_routes or {}
self.request_log = []
self.start_time = None
def _interceptor(self, request, **kwargs):
"""统一的拦截处理函数"""
# 记录请求信息
log_entry = {
'timestamp': datetime.now().isoformat(),
'url': request.url,
'method': request.method,
'headers': request.headers.copy(),
'resource_type': request.resource_type
}
# 检查是否需要 Mock
for pattern, mock_data in self.mock_routes.items():
if pattern in request.url:
request.fulfill(response_code=200, body=mock_data)
log_entry['status'] = 'mocked'
self.request_log.append(log_entry)
return
# 添加认证 Header
headers = request.headers
headers['Authorization'] = f'Bearer {self.token}'
headers['X-Test-Session'] = kwargs.get('session_id', 'default')
# 继续请求并拦截响应
request.continue_(headers=headers, intercept_response=True)
# 获取并记录响应
try:
response_body = request.get_response(is_auto_fill_response=True)
log_entry['status'] = request.status
log_entry['response_size'] = len(response_body) if response_body else 0
except Exception as e:
log_entry['error'] = str(e)
self.request_log.append(log_entry)
def start(self, session_id: str = None):
"""启动工作流"""
self.start_time = time.time()
session_id = session_id or datetime.now().strftime('%Y%m%d_%H%M%S')
# 注册拦截规则
self.router.intercept('*/api/*', self._interceptor, session_id=session_id)
self.router.start_intercept()
print(f"[{session_id}] API 测试工作流已启动")
def stop(self, report_path: str = None):
"""终止工作流并生成报告"""
self.router.end_intercept()
duration = time.time() - self.start_time if self.start_time else 0
# 生成报告
report = {
'session_id': datetime.now().strftime('%Y%m%d_%H%M%S'),
'duration': f"{duration:.2f}s",
'total_requests': len(self.request_log),
'mocked_requests': sum(1 for log in self.request_log if log.get('status') == 'mocked'),
'real_requests': sum(1 for log in self.request_log if log.get('status') != 'mocked'),
'logs': self.request_log
}
if report_path:
Path(report_path).parent.mkdir(parents=True, exist_ok=True)
with open(report_path, 'w', encoding='utf-8') as f:
json.dump(report, f, ensure_ascii=False, indent=2)
print(f"测试报告已保存至: {report_path}")
return report
# 使用示例
page = ChromiumPage()
mock_routes = {
'/api/users': json.dumps({
"code": 200,
"data": [{"id": 1, "name": "Test User", "email": "test@example.com"}]
}),
'/api/config': json.dumps({
"code": 200,
"data": {"feature_flags": {"new_ui": True, "beta_api": False}}
})
}
workflow = APITestWorkflow(
page=page,
token="your-test-token-here",
mock_routes=mock_routes
)
# 启动工作流
workflow.start(session_id="test-001")
# 执行测试操作
page.get('https://your-app.example.com')
# ... 执行各种自动化操作 ...
# 终止并生成报告
report = workflow.stop(report_path='./test-reports/api-test-001.json')
print(f"共拦截 {report['total_requests']} 个请求,其中 {report['mocked_requests']} 个为 Mock 请求")
注意事项与最佳实践
-
及时终止拦截器:使用完毕后务必调用
end_intercept(),否则会影响后续的正常网络请求。 -
避免阻塞回调:回调函数中应避免长时间阻塞操作,否则会影响浏览器响应速度。
-
合理设置拦截范围:使用精确的 URL 模式,避免使用
*拦截所有请求(除非确实需要),以提高性能。 -
处理响应体时必须填充:调用
get_response(is_auto_fill_response=False)后,必须手动调用fulfill()或continue_(),否则请求会挂起。 -
多规则优先级:当多个拦截规则匹配同一 URL 时,只有第一个匹配的规则会执行(按注册顺序)。
-
Base64 编码限制:大体积的请求体或响应体在 Base64 编码后会增大约 33%,注意内存使用。
总结
DrissionRouter 为 DrissionPage 用户提供了媲美 Playwright 的网络拦截能力,基于 CDP Fetch 域实现,支持请求修改、响应伪造、请求拒绝等完整功能。通过简洁的 API 设计,开发者可以轻松实现 Mock 数据、调试 API、性能监控等多种场景。
无论是前端开发中的 API Mock,还是爬虫中的请求调试,抑或是安全测试中的请求分析,DrissionRouter 都能成为你自动化工作流中的得力工具。


本文作者:回锅炒辣椒
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!